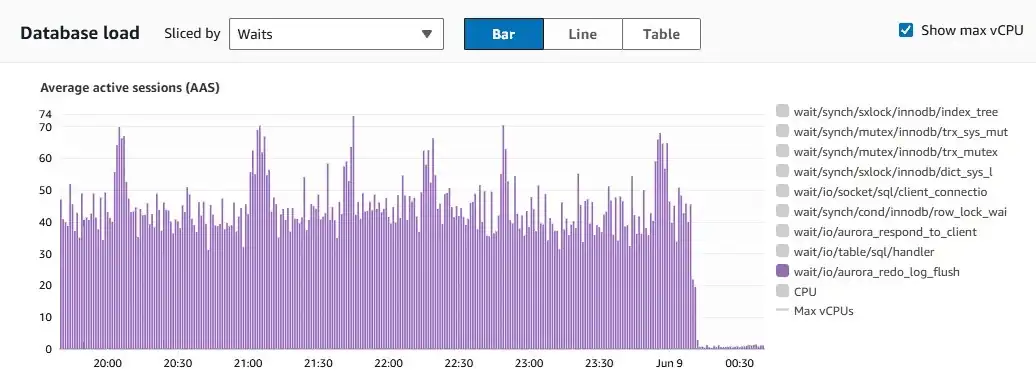
98% reduction in RDS io/aurora_redo_log_flush waits
Years in the making. Long-standing queuing issues eliminated.
Adventures in CI for Windows desktop apps
Our team took on some new responsibilities supporting the development of TestComplete, a functional UI testing tool
for web, mobile, and Windows desktop applications. TestComplete itself is a
Windows desktop application, so then the question looms, who tests the
testers? (No surprise, still us.)
Due to some limitations in Windows APIs and the way TestComplete works, we
could not find a way to test TestComplete with TestComplete. So instead we
landed on Robot Framework, a Python-based functional
testing program for Windows desktop. However, massive hurdles remained to be
cleared.
Functional desktop testing in Windows is not hard. Functional desktop
testing in Windows on headless CI agents is hard. Security around the
Windows desktop largely deals with the isolation of what Microsoft calls
"window stations." Interactive sessions get interactive window stations,
interactive sessions spawned by a non-interactive session (such as a new
session initialized by a CI agent running as a service) get a window
station, but in a sandbox with locked-down access to most system resources.
Two interactive sessions each get interactive window stations, but they
cannot interact due to process isolation rules that cannot be defeated.
If your CI agents are long-lived, it's not such a big deal. You can
initialize an interactive desktop session to a remote CI agent server with
Remote Desktop, then manually launch the CI agent process into that session.
All child processes of that foreground agent process will inherit the
interactive window station, and your functional UI desktop tests will run
just fine. But if your CI agents are ephemeral, there's no
opportunity to manually initialize that session.
So step one--initialize an interactive session immediately up CI agent
provisioning. Windows thankfully provides a way to auto-login an
Administrator user, which spawns an interactive session on the EC2
instance's "local" display. From now on, the CI agent is no longer headless.
It's pseudo-headless. It has a desktop, it has a virtual display, it
renders, but none of it is "real."
Step two--launch the CI agent into the foreground of the interactive
session, so all its child processes inherit access to the window station. A
simple Windows Task Scheduler task can be created to launch any process on
logon, to the foreground or background. In our case our CI system was
Jenkins, and the CI agent process was not actually the parent--the Jenkins
server connects to its ephemeral Windows agents via OpenSSH Server for
Windows and transfers the java agent binary for execution. So in this case,
SSHD was the parent process with access to the window station, the Jenkins
agent process was a child that inherits, and then the agent's child
processes, like Robot Framework, inherit that access too.
Even this was a challenge, as SSHD on Windows was designed to run as a
Windows Service, and security and filesystem access rules around it are
different when forced to run in foreground mode via sshd -d,
which is a debugging parameter. For security purposes when this debugging
parameter is used, the SSHD process cannot use password authentication, only
one connection is allowed, and the SSHD process exist on connection
termination. If launched as a non-Administrator, then SSHD cannot access the
system Host-Keys files, and initialization fails. Each of these problems
was, eventually, iteratively, found and solved.
Ultimately it was a long road to discover a not-very-complicated solution.
Our EC2 Image Builder pipelines now customize Windows Server images for this
purpose, rebuilding weekly for OS updates as well as on every new
TestComplete release. A dozen other customizations were necessary--the
virtual EC2 display defaults to 1024x768, which smushes desktop elements and
interferes with the Robot Framework tests. A dozen security features dealing
with remote access and session isolation had to be disabled. However,
considering the ephemerality of the agents and their lack of connectivity
back to internal systems, the risk was minimal.
The reward for weeks of effort was seeing a screenshot of a mouse click on a
desktop. And I'm the right kind of idiot to get excited about that.
That said, no one in this industry space likes Windows, and reasons like
this are why. "Programmatic", "automated", "scripted", "headless"--these are
all words that Microsoft doesn't consider when designing their systems. And
as the software development industry increasingly abandons the Windows
operating system, community support gets harder and harder to come by. For
as simple of a solution as this ultimately required, I couldn't find any
examples or write-ups anywhere of anyone doing it before.
Scaling feature envs for heavy E2E testing
At the request of our QA team, my self-service feature env system was extended to be
leveraged by our testing and integration processes. These environments were
originally conceptualized to allow parallel showcasing of in-development
features, but when designing the system I prioritized flexibility. The first
benefit of this flexibility has been enabling automated end-to-end testing
for every PR.
To handle the real-life representative workloads that E2E suites could
generate, we needed to scale the environments up at test runtime and then
revert to a cost-efficient scale at completion. This was made surprisingly
simple by leveraging Terraform's -target flag, though that
requires (perhaps unwisely) disregarding Terraform's own warnings:
╷
│ Warning: Resource targeting is in effect
│
│ The -target option is not for routine use, and is provided only for exceptional situations such as recovering from errors or mistakes, or when Terraform specifically suggests to use it as part of an
│ error message.
Surely nothing bad has ever happened from ignoring a warning like that. The risk has been worth it though, as it allowed me to deliver in two afternoons greatly enhanced testing coverage for every new feature in review.
Maintaining SMTP deliverability in an SMTP-hostile world
I maintain this page mostly as a portfolio to share my day-job projects, but
today I have to treat it like a blog. This is going to be a rant about the
ever-diminishing ability of independent SMTP operators to reliably send
mail.
Once upon a time it wasn't uncommon for people to self-host outbound mail
servers--in fact it was one of the most common system configuration tasks.
Unfortunately, years of spam and bad actors have eroded the faith in
individual outbound-mail operators. As more and more mailboxes come under
the control of centralized organizations like Google and Microsoft whom
never publish specific deliverability guidelines in an effort to stay
ahead of spammers, maintaining deliverability gets harder every year.
Further centralization with the rise of services like Twilio's
SendGrid allows for enhanced trust and collaboration between large central
mail services, leaving individual operators behind. In 10 years time, it may
well be entirely impractical to send mail from an "untrusted" source (read:
not SendGrid or AWS or Azure or...).
My team at SmartBear maintains around 300 outbound SMTP servers from which
we deliver monitoring notifications to our customers. The high number of
servers is by design and is central to our product's
decentralized-monitoring strategy. Since these are critical alerts,
maintaining deliverability is also critical. To this end I've had to develop
high-resolution monitoring solutions for several key metrics--IP reputation,
SPF validity, DKIM signing, proper reverse DNS resolution, and more.
Maintaining deliverability is a best-effort exercise. If Google updates
their ML mail scanning algorithms and suddenly decides it doesn't like our
notification format and incorrectly categorizes us as spam, that reputation
shift rapidly propagates to relays all over the world. DMARC reports can be
clean as a whistle, yet mail can still find its way to spam folders. With
each passing year the industry signals louder and louder--"if you want to
send mail, you have to pay someone to send it for you." This is a
tremendously unfortunate shift for an Internet that was the greatest medium
of free communication at its inception.
Fortunately for now, we can trick our way through the maze of sending
requirements. High TTLs on reverse DNS records help preserve deliverability
during third-party authoritative rDNS server outages. Programmatic
SPF-record generation and Route53's record APIs enable us to rapidly
manipulate our monitoring node pool's valid sender IP lists without
concerning ourselves with IP-trust issues. All-in-all we've managed to
create a reliable (though not fool-proof) network of outbound mailers that
takes surprisingly few man-hours to maintain thanks to clever monitoring and
automation, though the future for self-hosted SMTP looks grim.
Docker as a VirtualBox-Vagrant replacement for Apple Silicon
Our developers' local workflow was disrupted by Apple's shift to ARM CPUs
when VirtualBox announced it would not be supporting the new architecture,
nor would they be integrating CPU emulation features. Thankfully Docker
Desktop's underlying VM would be updated with Qemu CPU emulation. The
provided a ready-made solution requiring minimal churn in the search for a
replacement.
At first we considered following industry trends and moving development
environments to cloud environments leveraging my dynamic feature environments as a
provisioning/onboarding system, but concerns about costs and latency (with
our development staff spread across North and South America and Europe)
drove us to retain local development capability. Considering we already paid
for Docker Desktop licenses it made further sense to consolidate costs.
Vagrant already supports Docker as a native Provider and was fairly
straightforward as a plug-and-play solution.
Customer environment provisioning API with AWS Lambda
At SmartBear, one of our most in-demand SaaS products is Zephyr
Enterprise. Unfortunately, for years the customer trial spin-up
automation was poorly designed and prospective customers would face a wait
time of well over 25 minutes. The sales team was rightfully concerned with
the number of leads lost to slow trial delivery.
We set out to redesign the entire trial provisioning pipeline with a focus
on performance, self-service, and ease of integration. From the outset we
knew we wanted an API that the marketing team could use to request trials
and ping for trial status. The same API would offer trial extension and
termination functions for the sales and customer success teams.
As trials are inherently ephemeral, we knew we wanted to provision all
infrastructure with AWS SDKs instead of stateful IaC tools like Terraform
which can have notoriously slow executions due to state refreshes. We
selected Lambda for a zero-maintenance runtime environment and Python +
boto3 for maintainability as it is a lingua franca among our DevOps
teams.
Given that SmartBear is the steward of the open-source Swagger.io suite
of API development tools, we naturally elected to use AWS API Gateway for
request routing as it natively consumes OpenAPI/Swagger API definitions to
scaffold your Gateway for you.
Our team can proudly say that we delivered a fully-featured SaaS trial
management API to the sales and marketing departments that reduced customer
wait times from 25+ minutes to approximately 30 seconds.
Transient environments for Docker Swarm
Our development team grew to a point where our existing handful of Docker dev and QA environments became a bottleneck and started causing contention over feature deployments. In the past with a smaller team, it was uncommon for two or more developers to be simultaneously but separately working on the same microservices. To deal with this, I was tasked with finding a way to grant developers on-demand, dynamic, individual environments within the development Swarm cluster. Accomplishing this required every tool in our team's arsenal; Terraform, Python, Groovy, MySQL, Ansible, shell scripts, Makefiles, InfluxDB, and Jenkins came together like Voltron to build a system that could:
- Provision and assign individualized AWS infrastructure
- Tag all resources for cost analysis per-environment and per-user
- Isolate Docker image builds to avoid poisoning each other's build caches
- Support any size deployment, from individual microservices to full stack
- Dynamically modify container environments as neighbor services are spun up or down
- Alert on deployment inactivity to ensure against abandoned environments
The centerpieces that made this system possible are the Terraform
external datasource which enabled infrastructure
configurations to be fetched and generated from a centralized MySQL
environment metadata table, the Ansible docker_swarm
and docker_node
modules with which EC2 instances could be dynamically added to and removed
from the Swarm, and the Jenkins Extended Choice
Parameter plugin with which complex forms could be presented to users
for fine-grained control over environment configuration.
Trimming git object history
Many aeons ago, my organization managed an internal git server for all our
team's source code. Eventually a decision was made to migrate to GitHub,
starting first with new repositories and then later transferring existing
ones. All went well until they got to the last and most critical of all the
repositories--a 20+ year old behemoth that itself started life as a migrated
Subversion repository. Over the decades, users had made the poor decision to
check in large binaries. These binaries were eventually removed, but once
they're in git history the binary content is checked in forever, taking up
space. GitHub imposes a limit on repo import of a maximum 3 GB repo size and
100 MB maximum checked-in file size--our repo exceeded both.
I presented two potential solutions--adopt Git LFS, performing a migration of
binary files in history to LFS using git-lfs-migrate, or
simply strip all large files from history using BFG Repo Cleaner.
Migrating to LFS would preserve git history but incur a storage cost on
GitHub, whereas using BFG Repo Cleaner would alter historical commit IDs as
all commit hashes would have to be recalculated after the content was
removed from history. We decided that, given our relatively small team,
altering history was not a deal-beaker and we could simply all re-clone
after the repository was cleaned up. In the end, BFG Repo Cleaner shrunk the
repository to around 450 MB, a nearly 90% decrease in footprint.
Convert Compose v2 to v3
Our team has long-used docker-compose to manage container
workloads, writing compose files in the compose v2 format. I was tasked with
migrating us to Docker Swarm Mode which exclusively uses compose v3. I was
immediately concerned with the implications of maintaining two separate
compose files per environment and the potential that creates for
configuration drift, so instead I chose to develop a tool to translate a
given compose file in the v2 format to v3. This way, we would continue to
use the same v2 files we always had, and the deploy pipeline would
automatically convert the file to the required format at deploy time.
Initially I thought this would be a straightforward case of renaming certain
yaml keys, or trimming unneeded deprecated configurations. As I began
though, I realized that our organization made heavy use of the
depends_on and extends features of compose v2 that
had been deprecated with no equivalent or replacement as of version 3.8. The
challenge then became to find a way to replicate the behaviors v2 offered
during translation.
docker logs for multiple containers
If you simply google the title above, you'll see very many people asking how
to accomplish this task. The demand is so great that it's honestly amazing
that Docker have not extended the docker logs command to
support multiple containers. Even docker-compose logs will
output a stream of logs from all containers defined in the compose file! It
seems to be an obvious use-case to everyone but Docker themselves. So to
right this wrong I created a tool for myself that streams multiple container
logs directly from the Docker API. I placed a hard limit of eight
simultaneous streams in case this much concurrency could be a problem for
the API, though I've done no testing or research to see if this is even the
case.
Elasticsearch HTTP log query string indexing
Our team was looking for a way to aggregate and report on certain API usage
metrics which we could only retrieve from Docker-based HTTP logs. I had
previously implemented Docker log aggregation with Filebeat and Elastic Cloud. One of the
features of Elasticsearch is the ingest
pipeline where you can define parsing and mutation rules for
inputs prior to indexing. Many people use Logstash as part of the "ELK
stack" for this purpose, but it's less commonly known that parsing and
mutation can also be done on Elasticsearch itself, making use of existing
compute and reducing complexity in the logging stack.
I took the existing NGINX log ingest pipeline (provided by Filebeat) and
extended it to grok out the query string pattern from the
request URL. Once I had the query string separated, it could be split on the
& character and each key-value pair could be loaded into the
index using the kv processor. This made possible aggregation
queries to the effect of "select count(requests) where
url.fields.time_range is not NULL group by url.fields.time_range".
The resulting data from this example would be very valuable for determining
platform improvements, like optimizing web server cache time and InfluxDB
shard group durations.
{
"grok": {
"field": "url.original",
"patterns": [
"%{GREEDYDATA:trash}\\?%{GREEDYDATA:url.querystring}",
""
],
"ignore_missing": true
}
},
{
"kv": {
"field": "url.querystring",
"field_split": "&",
"value_split": "=",
"target_field": "url.fields",
"strip_brackets": true,
"ignore_missing": true
}
},
{
"remove": {
"field": "url.querystring",
"ignore_missing": true
}
}
Zabbix problem auto-resolution
Much of modern operations is based around automation. Monitoring and
observability are all very important, but if a person has to react and
intervene on monitoring alerts then that person becomes a bottleneck.
Eventually it was realized that if procedures and remediations could be
defined for operators in runbooks, then there's no reason that runbook
couldn't be executed automatically--this gave birth to tools like Rundeck.
We use many different monitoring tools internally. One of these tools is Zabbix, a MySQL-based system
monitoring suite. We like Zabbix for its flexibility--absolutely any
arbitrary data that you can generate at a shell prompt can be regularly
collected and monitored by Zabbix without the same kind of cardinality
issues that would affect most time-series based monitoring tools. An
extension of this capability is Zabbix Actions; the same way arbitrary shell
commands can be executed on remote hosts to collect data, arbitrary shell
commands can be executed when trigger conditions are met. Assume a trigger
that fires when a process $p dies, an Action can simply start
$p.
There was one problem to overcome with this: preventing Zabbix from
interfering with an operator. If for whatever reason an operator was
intentionally making changes that could trigger alerts, we didn't want
Zabbix to then be simultaneously firing off commands, causing confusion and
inconsistency. So a crucial requirement was to implement some form of idle
session detection--if users were logged in and not idle, then Zabbix should
never execute actions on that machine. If there were no sessions or idle
sessions, then Zabbix could go ahead and take its remediation steps. We
parse the w command for idle times, which counts time since the
user's last keystroke.
InfluxDB sample data generator
Time-series data is at the heart of the application I support. Our teams'
primary customer-facing product is (for the most part) a series of
dashboards and reports displaying metric data backended by InfluxDB. One day one of our
QA engineers was expressing that it would be easier to compare the
functionality of charts and graphs across different code versions if they
were always rendering the same data, regardless of when the
comparison was being done.
I took it upon myself to write a tool that could output a consistent metric
set to an InflxuDB instance for any arbitrary window of time. Using this
tool, the QA team could eliminate variability in data and perform more
consistent testing. Eventually I would like to extend this tool to output
data for other commonly used time-series databases, like Prometheus and
Graphite.
Ansible dynamic inventory
I came into a new role as a DevOps Engineer at SmartBear,
working on an application with some pretty unique infrastructure challenges.
In addition to a fairly standard AWS technology stack, my team had to manage
a fleet of about 300 additional servers located in around 30 different
countries around the world hosted in all manner of ways--colocations,
dedicated server providers, VPS services, and larger cloud providers. This
situation disallowed the "cattle, not pets" philosophy that is promoted in
modern DevOps and SRE.
Idempotent infrastructure for these 300-ish servers was not possible since
we had no direct control over system images or ad-hoc infrastructure
deployments. Given the restriction imposed by the underlying infrastructure,
ansible
was the primary tool used to align systems with as much identicality as we
could manage. To that end, ansible
dynamic inventory provided a very powerful way to centrally
configure Ansible-managed hosts.
Fortunately for us, our application already relied on a MySQL server
inventory table that we could leverage for Ansible inventory. A
host_type field mapped directly to Ansible host groups, and a
delimited string of feature flags could be passed as an array hostvar
enabling conditional execution of tasks. With these already in-hand, all
that was needed was a script to format each host row into Ansible
inventory-compatible JSON.
Locate users on the network
No matter how many times it has been brought up, a large percentage of
ticket submissions would come in with no identifying information on the
affected workstation. Growing frustrated, I took matters into my own
hands. I wrote a set of functions to search the organization's file
servers for connected users and their respective connected IPs. Since
every user accesses at least one file share, this was a fairly reliable
method of discovery. And since it didn't rely on querying neighboring
workstations, it was significantly faster than methods like PSTools'
PSLoggedOn.exe.
Stateful workstation reboots
For some unknown reason, our standard nightly workstation reboot GPO would
fail to wake clients for the reboot task. Looking for alternative
solutions, we decided on rebooting workstations after an explicit logout.
However, disconnected sessions and the Switch User button meant that if a
second user logged in and out, existing disconnected sessions would be
lost on the reboot, even if that session was just one hour old while the
user was out to lunch.
By parsing query user output, we could reboot conditionally
based on the state of active and disconnected sessions. We could even get
the idle times of disconnected sessions to only reboot when we could
consider it "safe." Doing this, we achieved our goal of frequent
workstation reboots but without the data loss risk typically associated
with such policies.
Ransomware detection with inotify
Most ransomware variants encrypt volumes recursive and usually traverse a
file system alphabetically. Knowing this, we can lay bait for ransomware,
and then sound the alarm when notice something suspicious. When working on
my Samba DFS project, I
created world-writable hidden directories at the root of every share, and
named them so they sat first in alphabetical order. In each directory were
thousands of almost-empty plaintext files. Using inotify-tools
to interface with Linux's inotify() function, I set up an
inode watch on every file of each hidden directory. When a threshold value
of files are modified or deleted, the server fires off an email containing
the connection information of the user(s) and IP(s) accessing those bait
files.
While the encryption program takes its time to encrypt all the thousands
of files (usually a handful of minutes), we are afforded the opportunity
to verify and then kill the malicious process ID. To take it a step
further, we can even block the IP on every shares' firewall with a single
Ansible command. The process is further automatable by killing the PID and
setting the firewall rule at another, higher threshold. Using this
approach, we've lowered our average frequency of ransomware events
(defined as events requiring a file system restore) from 1-2 per month to
zero.
Automated Samba share deployments for DFS
At my first organization, the existing network storage solution was a
single Windows Share on bare metal. The server was about five years old
and supported the entire 1,200 person organization. When ransomware got
popular, the lack of a proper permissions structure left it very
vulnerable to attack. I was tasked with decentralizing our storage, and
the solution I devised was a multi-server, department-segregated Windows
Domain DFS Namespace where the shared folders were actually Linux Samba
shares. Through the Samba configuration I could "invisibly" fine-tune
access control. Running the shares on Linux servers also gave me access to
tools like inotify() and auditd for rudimentary
intrusion detection.
At final count, I was planning 11 separate shares on 7-8 separate CentOS 7
hosts. To facilitate the deployment process, I developed a guided
interactive script to automatically manage the Samba and Winbind
configurations, as well as handle LVM management and base permissions.
Bulk AD account management with Exchange support
My first systems administration position was in a call center, and among
my responsibilities was Active Directory administration. Due to the nature
of the call center business, customer service representative turnover
rates were high enough that user account administration was a hassle.
Especially in the holiday seasons, we would frequently receive lists of
new hires and terminations 60+ users long. Prior to my scripted
solution, the established method of administering user accounts was to
manually create or delete them one-by-one in the AD Users & Groups GUI.
Needless to say, as the new-hires and terminations lists grew longer, I
grew more and more impatient.
My objective was to make the least annoying user management script I
could. No pre-formatted CSV files needed, or anything or the sort. Just
select an OU from a graphical dialog, paste in whole lists of proper names
(with some minor formatting caveats), follow the prompts. Easy,
annoyance-free, and greatly enhanced ticket turnaround time. There's still
quite a few more features worth adding, but even now it's one of the more
valuable tools I've created for myself.
Network querying & WakeOnLan with AD integration
When working on desktop inventory, provisioning, or deployment projects I would frequently need to monitor and maintain the online status of a subset of PCs within the organization. For example, when taking software inventory of only a single OU worth of PCs, I would first need to determine the sleep/wake status of all the PCs in the OU, wake the ones that are unresponsive, and keep them awake until the task has been completed. The company I worked at when I wrote these tools had a very "boots-on-ground" approach to this problem (i.e., walk to the computers and slap the spacebars), which I found less than efficient. I wrote these tools to solve that.
Compiling MAC address data for WakeOnLan
Developed in conjunction with my Wake-Send.ps1 PowerShell script, I needed a reliable
and up-to-date source of device MAC addresses on the network so I could
construct a magic
packet containing a target PC's MAC address data. Enter
macscanner.sh. Parses nmap output, self-cleans repeat entries,
is multi-hostname-aware, and requires no maintenance or afterthought. Runs
on any Linux server you have lying around that's online on your target
network. I run it on a 30 minute cron, and scp it to a network
location where Wake-Send.ps1 can access it.
Seething Corruption Trainer
A simple Python script to help memorize the Seething Corruption positioning call-outs on World of Warcraft's Mythic Archimonde encounter. Written because I'm bad at getting over failure. Pretty much useless to anyone but myself.
antonioabella.com
This site, hosted on a Digital Ocean Ubuntu LTS (14.04) VPS serving virtualhost pages with nginx and php-fpm. Created so I can hand out a website name and craftily appear to be a professional.
Desktop and mobile sites, form in PHP and JQuery, VOIP services
A landing portal and application form for a World of Warcraft raiding guild, server as a virtual host on this same server. Implements php-fpm for form manipulation and jQuery 1.11.2 via Google CDN. The desktop landing page uses a parallax effect design created in pure CSS. The mobile site is responsively designed for any resolution by leveraging the CSS3 viewport-height attribute. This server also hosts a Mumble VOIP server implementing SSL certificate validation for registered and elevated users.
CentOS 5.11 multi-role term project
A CentOS 5.11 server with SaltStack configuration management, several web services, Asterisk PBX, instant messaging server, extended logging services, backup management, network printing services, and more. Ran as a guest within a VMWare ESXi 5.5 host.
Windows AD/Exchange virtual lab
A virtual network hosted on VMWare Workstation 11 consisting of two Windows Server 2012 R2 servers, one CentOS 7 server, one Windows 7 Professional client, one Mac OS X 10.11 client, and one CentOS 7 client. One Server 2012 instance runs Active Directory, DNS, DHCP, and Routing and Remote Access to serve as a border router granting the virtual network internet connectivity. The second Server 2012 instance runs Exchange and IIS. The Linux server runs Apache and other miscellaneous services. The Linux machines authenticate to Active Directory with Samba/Kerberos, and the OS X client binds to AD with the in-built OS X OpenDirectory utilities.
Linux KVM hypervisor with KVM/Qemu Windows instance using IOMMU
A typical workstation machine running Arch Linux as the host alongside a Windows VM via KVM/Qemu. IOMMU (Input/Output Memory Management Unit) allows certain hypervisors to take control of assigned hardware devices including PCI controllers. In this application I pass a discrete GPU to the Windows VM which allows up to 95% of the native graphical performance within the VM enabling certain GPU intensive tasks such as gaming, video rendering, and hardware accelerated decode of very high resolution video. The two machines run concurrently with each GPU connected to its own monitor.